
- Have you found a PDF file that is not digitally searchable, and you really wish it was?
- Do you wish you could easily convert monstrously huge PDF files to more compact DJVU files, without a significant loss in functionality?
As a genealogist, I conduct a lot of research. You may already know that; but, did you know that it is possible to build desktop tools that truly help ease the research burden? I can tell you that it is.
In this posting, I’ll describe how you can address the two (2) problems noted at the head of this article, in the computing world I live in- Linux OS . I can’t speak for whether or not these features are completely “accomplishable” with either Windows or Apple. Perhaps some (one?) of our readers will offer those insights.
Let’s start with a brief description of the tools I’ve used to achieve the objectives mentioned. (If you want to find alternatives to my list of applications, below, you may use https://alternativeto.net/ to see what might work on your Desktop).
The applications I use include:
- Linux OS– I run MX Linux 18 Continuum a Debian Stretch Distribution. Any Linux distribution will be able to be modified to do what I discuss here.
- pdfsandwich– “pdfsandwich generates “sandwich” OCR PDF files, i.e. PDF files which contain only images (but no editable text) will be processed by optical character recognition (OCR) and the text will be added to each page invisibly “behind” the images. pdfsandwich is a command line tool which is supposed to be useful to OCR scanned books or journals. It is able to recognize the page layout even for multi-column text. Essentially, pdfsandwich is a wrapper script which calls the following binaries: convert, unpaper, tesseract, gs, and hocr2pdf (if tesseract < 3.03). It is known to run on Unix systems and has been tested on Linux and MacOS X. It supports parallel processing on multiprocessor systems.”
- pdf2djvu– “Its a known issue that PDF files containing many images can become horribly large. But there is a simple alternative to the PDF file format: DjVu files which use advance compression algorithms behave very much like their more popular big brother PDF, but convince with a reduced file size. “
- xfce4-terminal – “Xfce Terminal is a lightweight and easy to use terminal emulator application with many advanced features including drop down, tabs, unlimited scrolling, full colors, fonts, transparent backgrounds, and more.”
- Thunar File Manager– “Thunar is the file manager written for Xfce (Desktop Environment). File Managers help you organize your files, transfer files between your computer and other devices like Pen Drive, and helps you preview and easily copy also helps you perform a variety of custom actions.”
- pdf-to-djvu (script)- The script is attached as a ‘zip file’. This script will almost certainly need to be converted to run on Windows and may not work on Apple. Perhaps one of our ‘smart’ geeky readers can help with Win/Apple conversion.
All of the above applications need to be installed on your desktop. Use the recommended process for installing applications on your distriution.
The pdf-to-djvu (script) requires a slightly different process:
- Download the script from this post by clickling the link (above)
- Extract the script from the “zip archive”.
- Copy the resultant script, called “pdf-to-djvu”, to the following directory: /usr/local/bin/ Make certain the script is “executable”.
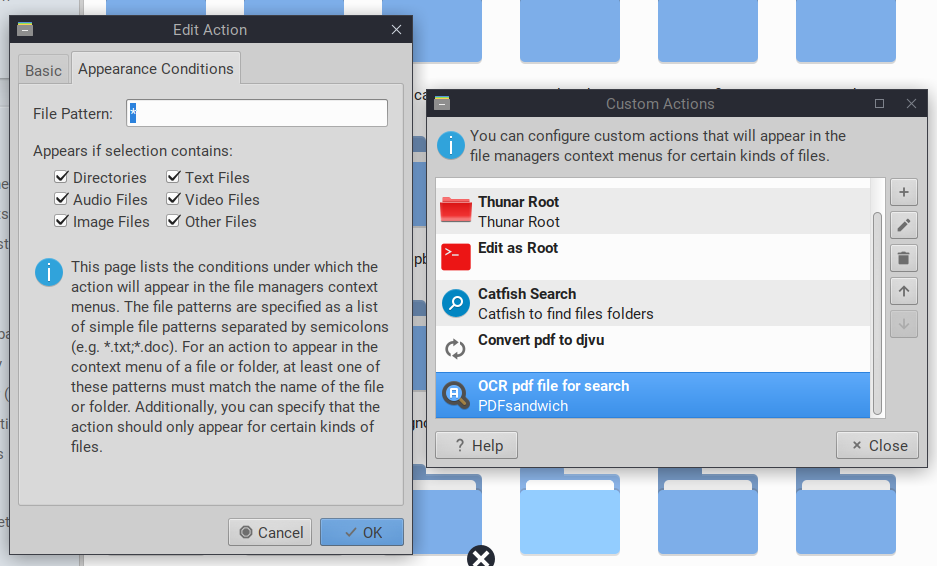
Once these installation, download and copy steps are complete you will need to add two (2) Custom Actions to Thunar. (Note: If you don’t know how to do that the process is described here.)
The Custom Actions need to look very much like the following images. (Yes you may tweak them, if you know what you are up to.)



After you have added these Custom Actions they should be fully functional. If you note any difficulty- simply log out & back in, that should make certain Thunar is reset and able to use your new commands.
Once the above tasks are completed, you will be able to:
- Convert PDF documents To DJVU (Note: The resultant DJVU documents will be searchable even if the original PDF was not… this only works for English, so far as I know.)
- Make a non-searchable PDF ‘searchable”. (Note: This only works for English, so far as I know.)
You must be logged in to post a comment.